|
|
You are here: Foswiki>Development Web>ReleaseProcess>FeatureRequest>AllowTypedData (21 Sep 2015, MichaelDaum)Edit Attach
Feature Proposal: Give DataForms, field types, registerMETA ability to specify type of data they hold
Motivation
1. Field entry validation
If a data form app is designed to use a number in a field, it should be able to rely on it - so that users don't need to put a check in every use of a field. This means we need to work out a way to tell someone that changes a form definition that what they're 'requesting' is impossible, or requires 'some list' of topics to be modified... - see Tasks.Item11026 for a little idea that might lead in a useful direction.2. Default sort style for SEARCH
Allow a form and field specific default for AddSortingBehaviourToSearch and SupportMultiKeySorting.3. Index generation for fast query caches
DBIStoreContrib, SolrPlugin and MongoDBPlugin have some great benefits over the BruteForce algorithm:- Unlike grep, which must parse entire topics, they can efficiently scan an atomised form of the topics, which reduces the volume of data that must be processed.
- If the data type is known, indexes can be used to simply lookup values - scanning often isn't required (or possible).
- If the data type is known, external databases can pre-sort results so that Foswiki doesn't have to. When there are many thousands of results in a web of tens of thousands of topics, this means Foswiki only has to fetch & process only the topics that are going to be displayed.
Description and Documentation
Foswiki has always been agnostic about data types. Our DataForms, QuerySearch and VarSEARCH users haven't had to think about data types before. Here are some "high-level" types, that might be further specialised by using + separated modifiers (much likeselect+multi+values is still a 'select' type):
Data types
- number
- number+integer
- number+real (base2 float)
- number+decimal (base10 float)
- datetime
- datetime+date
- boolean
- string
- string+varchar (for a long string)
- string+varchar+html
- string+char[255] (implied when the size ==255)
- case-less (there are times when we should really store 'thursday' irrespective of what someone's js sends us
- fwaddress, Eg.
- Some/Web/
- Some/Web.Topic
- Some/Web.Topic@3
- list (to benefit QuerySearch 's IN operator)
- list+<type>, Eg.
- list+string
- list+number+integer
- list+fwaddress
- list+<type>, Eg.
number and date (and possibly list, for some usages of QuerySearch 's new IN operator) will be immediately required.
- Sorting on number fields requires a
numberdatatype - Sorting on date fields requires a
datetimedatatype, but this can be automatically defaulted in thedatetype'sFoswiki::Formimplementation - Using QuerySearch 's new IN operator where the RHS is a formfield requires the
listdatatype
DataForms
Sadly, we need a way to specifynumber data type on a numeric fields, if users want to be able to sort on those fields correctly.
But we can provide a way for the Foswiki::Form field type to automatically set a default datatype, so for example the date field type would automatically default to a datetime+date datatype.
So, in practice, it should be possible for users to only care about datatypes when they're trying to sort on numbers.
Field types and their default data types
It's inappropriate for MongoDBPlugin to indextextarea because there's a small limit to the amount of data that can be indexed in a field. So in the case of string+varchar datatype, MongoDBPlugin simply wouldn't set an index at all. But SolrPlugin would. And DBIStoreContrib, might try to use a varchar index type appropriate for the SQL db it's connected to.
Foswiki::Meta::registerMETA
SemanticLinksPlugin makes use of this API, for example it registers aMETA:LINK datum ( many => 1 ) and we would love to do a query like this, which would take advantage of indexes:
%SEARCH{
"links[value='Some/Web.Topic']"
type="query"
}%
or perhaps the equivalent:
%SEARCH{
"'Some/Web.Topic' IN links.value"
type="query"
}%
Examples
Implementation
-- Contributors: PaulHarvey - 10 Aug 2011Discussion
For compatibility, it still has to behave correctly when data is not typed. There are three scenarios I can think of:- data is typed and the searching algorithm can sort on that data (will return a sorted result set)
- data is typed but the search algortihm is unable to sort on that data for some reason (e.g. the data type is not supported by the search engine)
- data is not typed
Field='value' presents a problem because Field might exist in several different forms, attached to different topics. If the data type is specified the same in all those forms, then no worries, but if not, how do you handle it?
Note that the data typing applies equally to search terms. For example, Field='01-04-2011' could be a string match, or a date match if the Field has a date data type.
-- CrawfordCurrie - 10 Aug 2011
MongoDBPlugin is missing a post-sort-search feature; that would be cool. I'm hoping if you're only fetching the datum on which you need to sort on, from say a resultset of 35,000 topics, that's going to be much quicker than the minutes of saturated network i/o it was taking for Foswiki to load/parse/process ACLs on each member of said res suultset (the problem we had prior to ACL filtering).
Regarding the second problem, I guess search engines could group/collect/table/namespace the fields by the form they're coming from (in reality, I'm surprised we've got as far as we have without making MongoDB collection-per-dataform, rather than collection/database-per-web). I haven't thoroughly thought that through: I've only been thinking of the minimum changes required from a plugin author/dataform user perspective.
As for the problem of query values not resembling stored/normalised/indexed values, such as with date... I guess we need new foo2foo() QuerySearch functions, like... Field=date('2001-04-01') or Field=date(OtherField) ? Ew...  we could make the second form illegal (only constant values allowed in the type-casting functions).
-- PaulHarvey - 10 Aug 2011
lets see what i can put together quickly.
we could make the second form illegal (only constant values allowed in the type-casting functions).
-- PaulHarvey - 10 Aug 2011
lets see what i can put together quickly.
- mentioning adding type ~~ string+html - perhaps this is a way to implement AddTextareaPlusRichToTWikiForms - '=Add a textarea+rich type to the TWikiForms definition that would cover the textarea with a wysiwyg html editor and store the contents of the field as html.=
-
caseless- so taht we store no-case, and search indexes can optimise for that too. (related to SearchOrderOnFormfieldNoCase - do we have case-less sorting in the *SortProposal* - adding some more important Motivations
registerMETA API
-- PaulHarvey - 15 Aug 2011
See also: ConvertDatesToISO
-- PaulHarvey - 30 Nov 2011
Idea: add an optional type attribute to META:FORMFIELD. If the META:FORM cannot be loaded, then use the type; otherwise use the type from the META:FORM. Update this field whenever the topic is saved and a form definition is loaded. At the moment if the form cannot be found all fields are given "text" type; this is a simple way to improve on that.
-- CrawfordCurrie - 30 Nov 2011
Great minds think alike - in fact I've been experimenting with this on our wiki. The idea being to nominate some fields as type 'fwaddress' which can be safely followed with OP_ref, but the idea is the same.
-- PaulHarvey - 01 Dec 2011
please, continue these thoughts - but don't forget to consider the flow-on of reducing the significance of the DataForm definition.
for example, if the typing info is in each topic, but the type changes in the definition topic - and thus is expected to change when rendering (without having updated the data topic)
given that iirc, editing a topic will update (as in remove) fields that are no longer in the dataform, and update them to the latest schema, knowing what the type was sounds handy - but even though you know the type, you've not addressed the change in how its rendered, or how to manage the required change to queries.
basically - its complicated, and the 2 opposing solutions would be: - manage changes to schema/view/query all at once - so if the dataform definition changes, all topics that use it are changed to suit
- consider the dataform definition as only an initial seed definition, but this requires a linkage to versioned query and view definitions, so that if a schema changes incompatibly, old topics can be viewed and queried the old way.
- Type in field is inconsistent with form definition.
- No type in field in topic
- Typed field exists in topic, but there is no corresponding field in form definition
- Field does not exist in topic but exists in form definition
- Topic view
- Topic edit
- Topic load (as in: I want to manipulate this topic in code)
- Query (search) over form data
view and edit react differently on DataForm changes.
Is it worth duplicating type info on each record? I am not convinced yet.
-- MichaelDaum - 01 Dec 2011
Well, the case I've got is that I want to draw a directed graph of topic links. This means only following formfields whose values really are valid topic names, and not, eg. some GATC sequence or a date.
Presently I've got a solution that works quite well, and without any knowledge of the dataforms it expects to encounter
But, perhaps the store can transparently add fields.type from the DataForm definition, to avoid polluting the actual topic.txt with unnecessary META:FILED.type keys
Just as I desperately wish we could have form.name.topic='MyForm', instead of form.name='MyForm' OR form.name='Web.MyForm' OR form.name='Web/MyForm'...
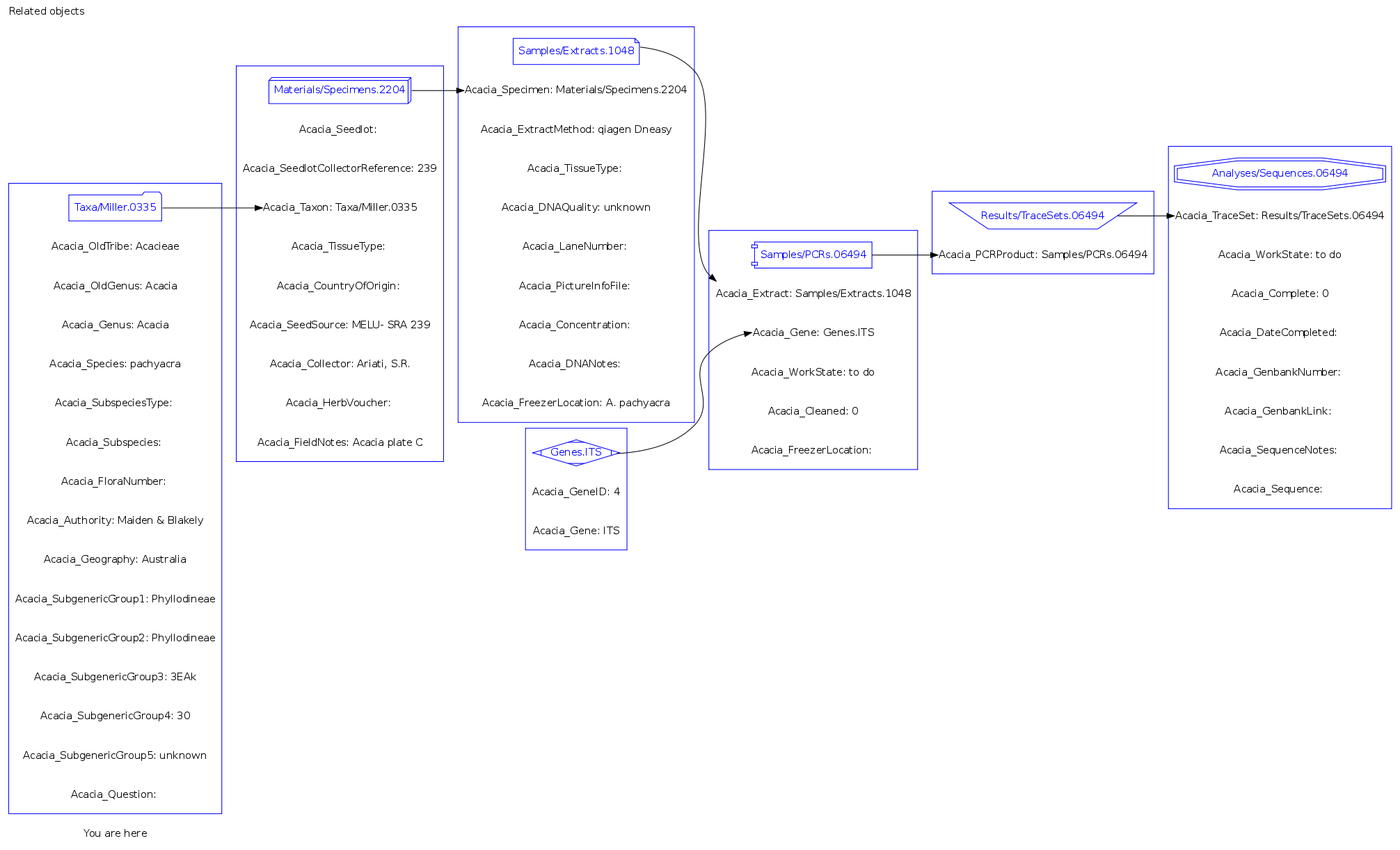
- acacia_pachyacra_LLB_sequence_view.png:

isodate fit in?
-- ArthurClemens - 22 Feb 2012
Change to "accepted" 24/2/12 - you might want to consider what release.
-- CrawfordCurrie - 24 Feb 2012
Note that multiple indexes are possible, for example: sort=SomeTextField will potentially be able to use an index (and sort quickly) on a back-end store that supports it. Whereas something simple like sort=uc(SomeTextField) would prevent the use of the index. To solve this either the index is defined as uc(SomeTextField) or if a raw and uc() searches are required then define both as indexes.
As noted sorting and indexing issues are close bedfellows. i.e. a query for 'LEVENS' = uc(SomeTextField? ) is likely to lose the benefit of the index.
On my work with VDBI, it has become clear that I may need to store fields two or more times: exactly as-is and indexable version(s).
Some extra indexes could be specified by the core or extensions
When VDBI is installed, it will be necessary to load the database from the text equivalent and I would like to store any field into a searchable form, but: - What do I do if the DataForm says "date" but the embedded META:FIELD says its text?
- What do I do if the DataForm says "date" but the embedded META:FIELD isn't given?
- What do I do if the DataForm says "date" but the embedded META:FIELD is given but has a blank value?
- What do I do if the DataForm says "date" but the embedded META:FIELD is given but has an invalid value?
- Take the type as date. With an SQL back-end, every field must be of the same type to be of any use.
- Store as a NULL? (undefined in QUERY speak)
- Store and hence query/sort with a date of '0000-00-00' or '9999-99-99'? Or also treat as NULL?
- Store and hence query/sort with a date of '0000-00-00' or '9999-99-99'?
- Unstructured: i.e Natural language; paragraphs, sentences & words
- Loosely structured: Headings, Tables etc
- Formal structure: DataForms
- Now under control of Foswiki via the UI
- But can be damaged by direct manipulation of the text files
- But over time datatypes can changes
- Strictly structured:
- Now under DB control, types controlled across the board not just one field at a time
- Direct DB manipulation can possibly damage structure but less likely, it's not a valid API in any sense
- Versioning side must handle change types over time, but the change is necessarily across all fields not just the next update of one topic
lc('%URLPARAM{"q"}%')=lc(SomeTextField) on webs with on the order of 50-60,000 topics, and lack of indexes isn't really an issue here (unless used in a nested SEARCH).
This multiple-index strategy is what Solr does best; in fact, I wish I had the time to write a query algo using Solr - although it's not expressive enough to run much of the QuerySearch language, many simpler expressions should be possible.
-- PaulHarvey - 27 Feb 2012
I have found that hybrid search algos - running simple hoisted searches, such as full-text searches using Sphinx - to narrow down the set of potential topics, then using brute-force to perform a final search, successfully accelerates 90% of searches (which are usually looking for a narrow set of topics). Don't get too hung up on complete coverage in the index - it's a good goal to have, but expect a leprechaun to be waiting for you with a pot of gold when you achieve it.
-- CrawfordCurrie - 28 Feb 2012
Crawford: I've been in SQL land quite a bit lately especially wrt indexes, as a result my thoughts above do give the impression that I'm trying to create perfect indexing. I also had the CreateISODateFormat proposal on my mind and it's specific needs.
Well I'm not trying to create perfect indexing.
VDBI will by its nature index every field, but only as a string. Actually that's simplified. Things like date and number could be indexed by storing a canonical text version that sorts (and hence indexes) appropriately. However, I'll probably add a table for all date fields for efficiency, specifically allowing the SQL engine to do a lot of the work. I will need something similar for numbers. Everything else can be a string.
Starting from where we are, this will be a significant speed-up (as you confirm) which for the general Wiki and App usage will be (I hope) more than enough. If someone needs more performance then there's nothing stopping some further tweaking, but let's wait for these needs to appear and then worry about them.
I'm very much in favour of the work here, I dare so we all have some misgivings, but we'll only sort those out as we work on things. My VDBI work is certainly generating a lot of questions and ideas in my mind.
Finally, I do not believe it is possible to have a completely store-agnostic solution to this. Actually it is, but only if you sacrifice making the best of the stores abilities — which is a mostly about performance.
-- JulianLevens - 28 Feb 2012
I really need to share what we've learnt with our Mongo adventure: if you want efficient queries over 10,000s of topics, it is crucial to avoid chattiness, to delegate as much of the query/filtering to the DB as possible. I can't stress that enough: this is drastically more important than fiddling with indexes - in fact I can have all indexes disabled and Foswiki still struggles to formulate a query convoluted enough that Mongo can't answer it (under production load!) inside of a second or three (we have ~230,000 topics, largest web ~65,000). (Actually, that's a lie - some d2n() queries (I think there's a bug wrt nulls) and especially OP_ref queries - these aren't native query ops, we execute a javascript program on the server - can take 10s of seconds on the larger webs).
Whenever Foswiki must load thousands (or even hundreds) of topics into memory, that totally dwarfs any DB query times, indexed or not. Example: - We had a web of ~35,000 topics
- query looked something like
"form.name='Web/Topic.DataForm' AND Status='Foo'" - Mongo's
explain()indicated that this was a reasonably fast query (using indexes), even when loaded with real traffic on prod: circa 5-10ms - Nonetheless, with most of the topics ACLs set so that only SpecialGroup could view them, non-admin users experienced page view times of up to two minutes to get the first page of 25 hits!
- Profiling indicated Foswiki was sucking in almost all 35,000 topics (~200MiB!) on each view - to check ACLs, and hide hidden stuff from the result
- Sven then added the ACL filtering code, so that ACL filtering was delegated to mongo. WikiGuest, SpecialGroup, non-special users alike were all able experience ~1.6s page views
list+number, but I see I didn't tackle the problem of giving an appropriate view = select.
Hrm. I really will try to get my datum-handler thingy into a workable state, which tries to be an MV(P)C architecture to replace Foswiki::Form - initial inspiration was the disconnect between Foswiki's (X)HTML-centric renderForDisplay/Edit vs other views that we wanted (RDF, CSV, jqGrid, etc).
-- PaulHarvey - 10 May 2012 - 23:58
This feature proposal has lost its developer. Discussion is stale for 3 years. It still is unclear how types are assigned in DataForm definition. There doesn't seem to be consensus about it and no such definition in the proposal description as far as I can read. For this reason I have to raise concerns.
-- MichaelDaum - 21 Sep 2015
ChangeProposalForm edit
| TopicSummary | Allow data forms, Foswiki::Form field types and registerMETA to specify data/index types for query/search algo's w/indexes |
| CurrentState | ParkedProposal |
| CommittedDeveloper | |
| ReasonForDecision | NoCommittedDeveloper |
| DateOfCommitment | 14 Aug 2011 |
| ConcernRaisedBy | |
| BugTracking | Tasks.Item10437 |
| RelatedTopics | Tasks.Item10721, ConvertDatesToISO |
| PlannedFor |


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
acacia_pachyacra_LLB_sequence_view.png | manage | 131 K | 15 Dec 2011 - 23:39 | PaulHarvey |
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r25 < r24 < r23 < r22 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r25 - 21 Sep 2015, MichaelDaum
The copyright of the content on this website is held by the contributing authors, except where stated elsewhere. See Copyright Statement.  Legal Imprint Privacy Policy
Legal Imprint Privacy Policy
Legal Imprint Privacy Policy